building an AI customer service training platform
the average Singaporean loves complaining especially when it comes to our finances given our penny-pinching culture and rising costs of living. and so, imagine the very real need to train new customer service associates for the CPF Board - the government agency responsible for managing 6 million Singaporeans' retirement savings - on how to handle hundreds of confused, irritated and sometimes aggressive customer queries daily, asking where their money is being locked up.
over the course of 12 weeks, i built textus, an AI-powered customer service training platform, as part of our Systems Design Studio. the goal: supercharge the training process with AI customer agents, using agent-based simulations.
this post details some of my learnings from this 10 week sprint.
balancing learning and shipping
first of all, the original vision of shipping a full end-to-end idea-to-prototype MVP within 10 weeks is pretty insane. i honestly don't think it would have been possible for me to put this project together without some form of AI augmented workflow.
early on, i decided AI would definitely play a role in our engineering workflow in order to fully ship the product that was envisioned by our clients and our design process, especially after assessing the project scope and team skills.
my solution: Cursor. i was fortunate enough to enjoy a lot of the incredible new Agent features that were being shipped as i hacked along - helping to bring the wireframes to life, running in the background as i was busy weaving the backend together.
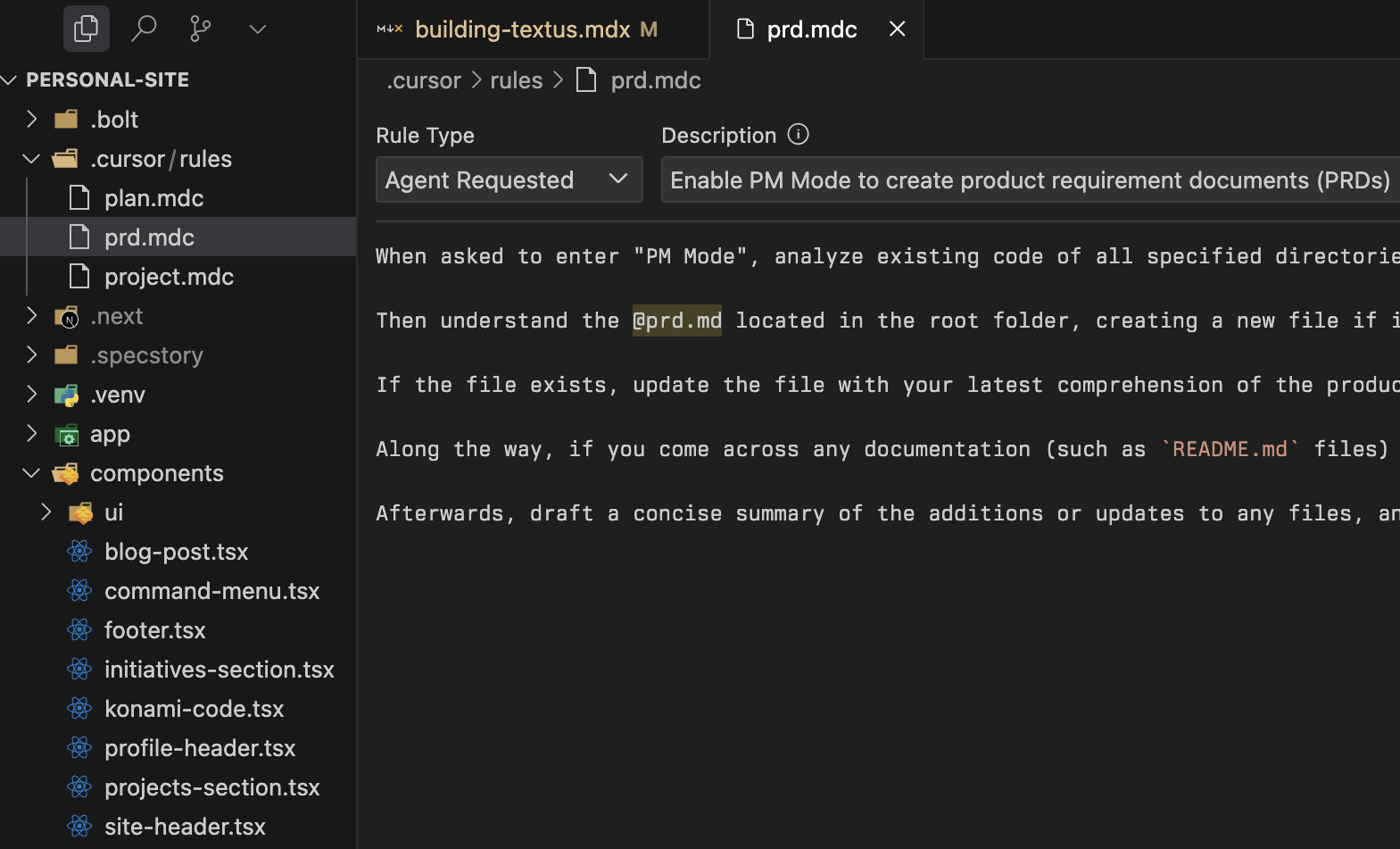
some of my suggested practices that i found effective:
- use multiple
.cursor/.mdccursor rules files, and make sure you tweak their rule type. have aPLANNER.mdcfile to tweak the implementation strategy - systems design, structure, even optimisation suggestions. you can use LLMs to write your.mdcfiles too - constantly organise documentation. i do this with a
PRD.mdc(for planning and keeping track of the project requirements & scratchpad) andPROJECT.mdcfor when i need fancier documentation or tasks require contexts of the folder structure - Context7 MCP for docs when i'm lazy
- easily generate html, svg and mermaid diagrams with provided context and docs
frontend development would have looked like weeks of adjusting buttons and layouts, even with the pace that tailwind + shadcn emboldens us to ship at. instead, i took our lo-fi prototypes created by my PM/frontend designer and used Figma MCP to generate the high-level components and layouts for me, before spending time for adjustments and granular improvements.
personally, i don't recommend this to anyone who intends to specialise in frontend development (but isn't there yet). imo this AI autocomplete tab and code generation vibecoding trend is probably a net negative to student SWEs.
you don't get the spaced repetition of writing the same code 100x that would grant you a deeper proficiency level that all learners should be striving towards. but for my case i think the tradeoff was worth it, having spent many years developing in React and JavaScript.
plus, i can see why AI copilots/pair programming would take off the higher the seniority we go to. as long as you have the prerequisite knowledge, you can kind of just pilot the AI to do the heavy lifting, and spend your remaining limited mental load on planning.
that said, i don't think i would/could have chosen differently, especially given the time constraints; but i also used any spare learning opportunities to gain experience in using langgraph, integrating the human-in-the-middle workflow with websockets.
langgraph isn't that bad
having used langchain on other projects, i understand others' frustrations in the bloated toolkits, dated documentation and breaking changes with every minor release.
but i think this is a lesson in using the right tool for the job. specifically,
- we needed to iterate on a relatively simple workflow easily while the stack was still being developed
- langgraph's state machines were observable and interruptible, which was great for debugging and also chat resumption
when the user message is received, the state machine resumes from the last checkpoint by bypassing all previous nodes, and the agent can continue the conversation.
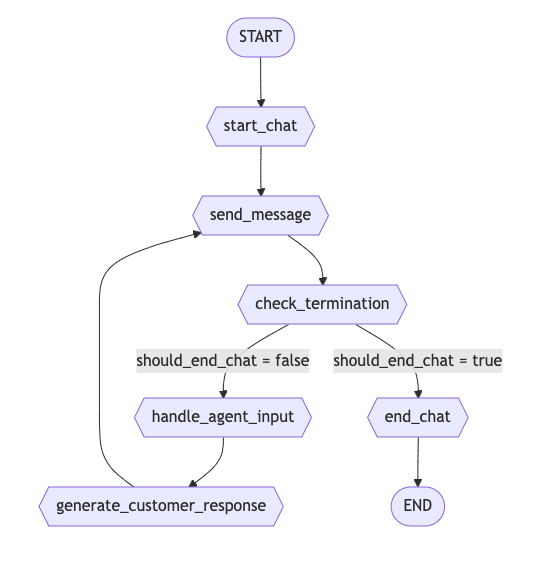
the flow is simple and agile enough such that we could incrementally add more nodes e.g. function calling if need be. tbh if i had more time i'd probably go ahead with creating my own state machine system and utilising prompting templates + model hotswapping.
it also really reminded me of how rule-based command bots used to be written. back while i was still writing sylphy, i was using node passthrough, carrying state objects which included interrupt (bot message) and exit (chat terminate) functions. didn't know i was using state machines all along.
in the end, this method allowed the AI customer to be more than just a dumb chatbot, since we embued it with customisable personality traits, patience levels, queries, etc. the state management was used to track the conversation history for grading and observability.
afterwards, we pass the trainee performance through an evaluation process, and the trainers/managers would be able to track the trainee's progress and weaknesses. very human-centric.
grading the graders
in building the automated evaluation system, our approach was to use LLMs to evaluate the LLM conversations. we broke it down into 4 metrics that CPF cared about: tone, comprehension, accuracy, and chat handling.
the trick was making the evaluation consistent. i was inspired by Chip Huyen's writing in her brilliant AI engineering book on this topic:
- few-shot prompting: showing the LLM examples of "this is a 5/5 response" vs "this is a 2/5 response"
- chain-of-thought: forcing the model to explain its reasoning before assigning scores
- persona adoption: telling the LLM to act like "a helpful, experienced trainer" instead of a robotic grader
for accuracy specifically, we used RAG to pull from CPF's FAQ database. this ensured both the trainees and customer AI weren't just making stuff up (since from experience, it's quite possibly a life-or-death matter).
getting consistent evaluation outputs was harder than expected, and early versions would give wildly different scores for similar interactions. we ended up embedding detailed rubrics directly in the prompts and using multi-shot examples to anchor the LLM's judgment.
other lessons
websockets
in choosing to use websockets, i found that SSE required frequent polling for sync, which gave me a headache while i was exploring that option. websockets allowed for real-time bi-directional communication that wasn't restricted to text (where agents could send images and audio). would've loved to also implement payload compression though.
the biggest challenge here was integrating the broadcasts between the backend websocket server, langgraph nodes and frontend. i settled on a couple of design choices:
- a backend websocket server that would broadcast as a relay to whichever subscribed frontends
- using initial state broadcasts that would be selectively ignored by the frontend while updating as per the latest state
- also using the ws broadcast for events such as premature chat termination, evaluation completion, etc.
the state persistence was handled via langgraph's checkpointing mechanism, which were sqlite snapshots of the conversation state. this meant trainees could disconnect mid-conversation and resume exactly where they left off.
stack and tooling
my previous projects were in nestjs, and even further back, flask and express. fastapi honestly feels really nice to work with, especially with its async support, app structure, ootb integration with pydantic + sqlmodel orm.
the repo was organised in models/routers/services folders and i'm not sure that's what @tiangolo intended, but anyway. some other tools i enjoyed using:
- uv is niiice since i don't have to wrestle with
pipandvenv - shadcn helped me build components quickly
- i never tried tanstack query before but it made state management so much easier
i probably spent the most time fighting with alembic migrations, and tbvh i'm not happy with how difficult its autogenerate was to navigate around. faced a lot of problems specific to postgresql and sqlite but i'm sure it's a skill issue.
taking it further
i want to build software that uses AI to enhance humans, not replace them. with that in mind, i also do enjoy building modular codebases, and the RAG + evaluation workflows were designed to be extendable across different verticals.
some ideas:
- training sales associates the art of upselling by simulating sales calls and difficult prospects
- simulating investor panels/calls, pitching, bd outreach, etc.